I began a project which required a small amount of data – about 100 byes to be written into MySQL database each second or two.
At that time there were another project on my server which wrote into the database once in 15 seconds.
I use Innodb database engine and each write procedure was a separate commit so it entails actual write to the disk.
Somehow I didn’t bother about writes once in 15s, but had become worried before deploying the project which should make writes once per second.
I don’t know (or remember) the exact behavior of all the layers which my small portion of data should get through, but I know that there should be a few pitfalls.
1) I use Innodb and each committed write procedure must be flushed to disk. There is no (known for me) way I can avoid this. The best I can do is to reduce disk flushing to one flush per second but it doesn’t make sense in my case. It could help only if I had 100 transactions per second or so.
I didn’t want to combine many write procedures into the one transaction because I needed real time values in database.
2) My portion of data is small – about a hundred of bytes, but file system can preform writes only by blocks and those blocks are at list 512 bytes. There is also could be write/erase overhead because physical page size of SSD is different from logical size (in my case logical size is 512B and physical is 4096B), and I’m not sure that any of them has to do with the page size of an actual NAND chip, that, which can’t be overwritten and must be erased.
3) Like the file system, Innodb writes data in pages. Each page is about 16KB. So it is wise to anticipate some overhead here too.
I’m not sure in any of my previous statements, because I wasn’t interested to dig into such subtle questions.
Maybe I could change the way Innodb does disk flushes to avoid actual flush and to hold data in the file system’s buffer for some time. But I didn’t see the easy way to do this and I think this is too serious interference with database internals and the way it is intended to work.
I actually do not know the size of cluster on my file system and how it connected with NAND page size.
I’m not sure that “commit” operation requires writing into table space, which has paged structure. Maybe for MySQL is sufficient to write a compact form of transaction into the innodb file buffer. But anyway, ACID requires data to be written on disk after each transaction.
So, I had a few uncertainties to worry about and I decided to check SMART attributes of the disk under load.
On my server I use Ubuntu 16.04LTS and MySQL server from repositories.
The system drive is 3-years old Crucial M550, which is 75% empty
At the time of beginning the test this drive had
Power_On_Hours 9211
Ave_Block-Erase_Count 297
Percent_Lifetime_Used 9
Unfortunately, during the test I didn’t watch counters concerning page writes or page erasures. I only can say that this disk already had quite large Write amplification Factor = 8.5
After beginning of the test, during which I had two services, performing commits into MySQL Innodb database, the first service one commit in 15 seconds and the other one commit in 1-2 seconds, I got these results:
| timestamp | Power_On_Hours | Ave_Block-Erase_Count | Unused_Reserve_NAND_Blk | Percent_Lifetime_Used |
| 2018-08-20 00:00:00 | 9210 | 297 | 2159 | 9 |
| 2018-08-23 22:22:00 | 9218 | 298 | 2159 | 9 |
| 2018-08-25 21:00:02 | 9265 | 299 | 2159 | 9 |
| 2018-08-27 03:00:02 | 9295 | 300 | 2159 | 10 |
| 2018-08-28 03:00:03 | 9319 | 301 | 2159 | 10 |
| 2018-08-29 00:00:02 | 9340 | 302 | 2159 | 10 |
| 2018-08-30 00:00:02 | 9364 | 303 | 2159 | 10 |
| 2018-08-30 21:00:02 | 9385 | 304 | 2159 | 10 |
| 2018-08-31 21:00:03 | 9409 | 305 | 2159 | 10 |
This is where I stopped the torture.
As far as I understand, this table means that whole my SSD was being overwritten each day by two small (~60MB each) MySQL tables. It seems that process was accelerating.
This is a situation which usually mentioned as impossible, when speaking about SSD lifespan (usually about new type of SSD with lesser endurance 🙂 )- full overwrite each day.
Even in such condition this SSD, of course, could live for several years before its lifespan (3000 erase cycles) will have been exhausted, but I decided to change my services to reduce the frequency of write operations.
My services became little more complex, I refused to write unnecessary data and made a buffer for data to reduce write frequency to 5 minutes. This buffer is flushed into database in one commit now. I also was forced to make a separate channel to my services to get a real-time data from them and not from database.
Since that changes had been made (5 days ago) there were no increasing of Ave_Block-Erase_Count.
I will update this article when new data for Ave_Block-Erase_Count appear and the speed of block erasure in new circumstances become apparent.
Update
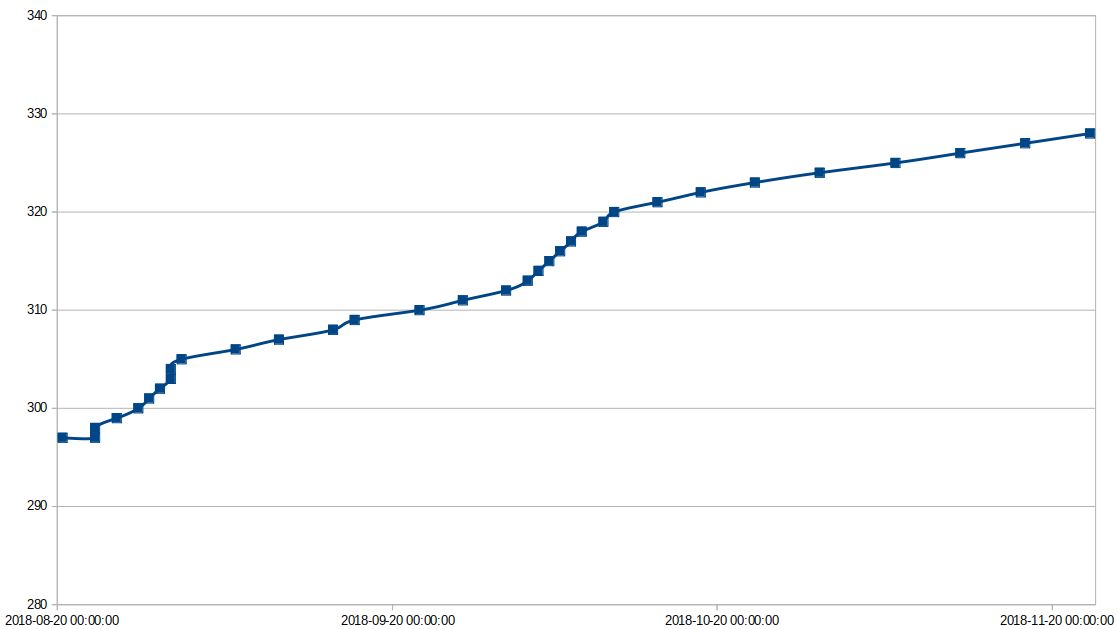
Here is the full data up to current moment.
You can see the period of initial rapid wearing, period where I reduced writes into DB.
Then I made a mistake in one of my scripts and Erase_Count began to grow rapidly again 🙂
Then I found the bug and the wearing speed reduced.
I also made changes in fstab – added option COMMIT=600 for the root mount point but, as far as I can tell, this hasn’t made any changes. Perhaps, because MySQL does its flushes on its own using fsync().
For some time I considered using anything-sync-daemon or something like that for /var/log directory, but found it too precarious.
| timestamp | Power_On_Hours | Ave_Block-Erase_Count | Unused_Reserve_NAND_Blk | Percent_Lifetime_Used |
| 2018-08-23 17:27:24 | 9211 | 297 | 2159 | 9 |
| 2018-08-20 00:00:00 | 9210 | 297 | 2159 | 9 |
| 2018-08-23 22:22:00 | 9218 | 298 | 2159 | 9 |
| 2018-08-25 21:00:02 | 9265 | 299 | 2159 | 9 |
| 2018-08-27 03:00:02 | 9295 | 300 | 2159 | 10 |
| 2018-08-28 03:00:03 | 9319 | 301 | 2159 | 10 |
| 2018-08-29 00:00:02 | 9340 | 302 | 2159 | 10 |
| 2018-08-30 00:00:02 | 9364 | 303 | 2159 | 10 |
| 2018-08-30 21:00:02 | 9385 | 304 | 2159 | 10 |
| 2018-08-31 21:00:03 | 9409 | 305 | 2159 | 10 |
| 2018-09-05 06:00:02 | 9515 | 306 | 2159 | 10 |
| 2018-09-09 09:00:02 | 9614 | 307 | 2159 | 10 |
| 2018-09-14 09:00:02 | 9735 | 308 | 2159 | 10 |
| 2018-09-16 18:00:02 | 9792 | 309 | 2159 | 10 |
| 2018-09-22 06:00:01 | 9925 | 310 | 2159 | 10 |
| 2018-09-26 03:00:02 | 10018 | 311 | 2159 | 10 |
| 2018-09-30 00:00:02 | 10110 | 312 | 2159 | 10 |
| 2018-10-02 00:00:02 | 10158 | 313 | 2159 | 10 |
| 2018-10-03 03:00:03 | 10185 | 314 | 2159 | 10 |
| 2018-10-04 00:00:02 | 10207 | 315 | 2159 | 10 |
| 2018-10-05 06:00:01 | 10237 | 316 | 2159 | 10 |
| 2018-10-06 12:00:01 | 10267 | 317 | 2159 | 10 |
| 2018-10-07 21:00:02 | 10300 | 318 | 2159 | 10 |
| 2018-10-09 03:00:02 | 10330 | 319 | 2159 | 10 |
| 2018-10-10 06:00:02 | 10357 | 320 | 2159 | 10 |
| 2018-10-14 21:00:02 | 10469 | 321 | 2159 | 10 |
| 2018-10-18 21:00:02 | 10562 | 322 | 2159 | 10 |
| 2018-10-23 03:00:02 | 10665 | 323 | 2159 | 10 |
| 2018-10-29 06:00:02 | 10813 | 324 | 2159 | 10 |
| 2018-11-05 00:00:02 | 10975 | 325 | 2159 | 10 |
| 2018-11-11 12:00:02 | 11132 | 326 | 2159 | 10 |
| 2018-11-17 00:00:02 | 11265 | 327 | 2159 | 10 |
| 2018-11-23 12:00:02 | 11422 | 328 | 2159 | 10 |